LLM(大規模言語モデル)を分かりやすく解説|仕組みや建設業での事例

目次
トレンドワード:LLM(大規模言語モデル)
「LLM(大規模言語モデル)」についてピックアップします。ChatGPTにも活用されている技術で、膨大な情報をディープラーニングすることで高品質な文書を生成できます。本記事ではLLMの仕組みや課題、建設業での活用事例についてご紹介します。
LLM(大規模言語モデル)とは

LLM(Large Language Models)とは「大規模言語モデル」のことで、自然言語の理解と生成を行う人工知能の一種です。膨大な量のテキストデータをディープラーニングで学習することにより、特定のタスク(質問応答、文章生成、翻訳など)に対して高い性能を発揮します。
具体的には、OpenAI社の「ChatGPT-4o」等が挙げられます。こちらはLLMの技術を応用した対話型AIで、音声入力や画像認識も可能という点が特徴です。
LLMでできること
LLMの技術でできることとしては、下記が挙げられます。
- 翻訳
- 対話システム
- テキスト解析
- 情報検索と抽出
- コード生成
- 教育・学習
LLMを用いることで、異なる言語間でのテキスト翻訳が可能になります。また自然な対話形式で問い合わせに答えられるため、サポートツールとしても活用できます。
またLLMを用いた対話型検索エンジンも開発されており、よりユーザーの意図に沿った提案をしてくれる場合も多いです。プログラミング言語に対応していることから、簡単に指示するだけでコーディングを作成することも可能です。最近では英会話練習用のツール等、教育分野での活用も目立ちます。
LLMの仕組み
LLM(大規模言語モデル)の仕組みを簡単にまとめると、下記①~④の流れとなっています。一般的には、「〇〇について教えて」といった口語形式の指示を与えるだけで利用可能です。
①トークン化
トークン化とは、テキストデータを単語やサブワードに分割するプロセスのことを指します。膨大な量のテキストデータを「トークン」と呼ばれる最小単位に分割・変換することで、コンピュータが理解しやすくするのです。
②エンコード
エンコードとは、データを規則に従って変換することを指します。トークンを特徴量(数値情報)として抽出することにより、コンピュータが解析可能な形になります。トークン同士の関連性や類似性をベクトルとして数値化することで、文脈が把握できるのです。
③デコード
デコードとは、変換されたデータを基の形式に戻すことを指します。確率から次に来るトークンを予測し、新しい文章を作成します。
デコードされたトークンは再びテキストデータに戻り、ユーザーに対する適切な出力(回答や生成テキスト)を提供します。このプロセスが繰り返されることで、複雑な自然言語の理解と生成が可能になるのです。
LLMと生成AIの違い
LLMは、主に自然言語処理に特化したモデルです。言語データを理解し、テキストを生成する分野に強みがあります。一方で生成AIは、テキストだけでなく画像・音声・動画など様々な形式のデータを生成するAI技術の総称という違いがあります。
つまりLLM(大規模言語モデル)は、自然言語処理をすることによって翻訳や文書の要約作成などができるAIと言えます。
LLMのデメリット・課題

LLMにはメリットが多いですが、開発段階の分野のためまだまだデメリットや課題も存在します。
開発コストが掛かる
LLMの開発には、膨大な量のテキストデータが必要です。データを収集するには多くの時間やリソースが求められ、開発コストに影響を与えます。
また高性能なハードウェアの利用、長期間のプロセス、専門知識を持つ人材の確保、インフラの構築など、多方面にわたるコストも掛かります。こういった要素が重なることで、一部の大企業や研究機関に開発が偏っているのが現状です。
情報の信頼性が低い場合がある
LLMは便利なツールですが、情報が信頼性に欠ける場合があります。インターネット上の広範なデータを基にディープラーニングを行いますが、このデータには誤った情報や偏った情報も含まれていることが主な理由です。
場合によっては、性別、年齢、地域、民族などに関するバイアスが含まれることがあります。これにより、不適切な情報が生成されてしまうのが課題です。
またモデルの訓練には一定の期間を要し、その間に新しい情報に更新されていることもあります。しかし最新の情報を反映できない場合、生成される情報が古くなってしまいます。
そのためLLMを利用する際には、情報の信頼性をしっかりとチェックする必要があります。
情報漏洩のリスク
LLMの開発では、大量のデータを必要とします。その過程でサイバー攻撃を受けると、個人情報や社内情報が漏洩してしまうリスクが生じるのです。
またLLMを利用する際にも、機密情報を含んだ内容を送信することでLLM側に情報が渡ってしまいます。これにより、競争力の低下や経済的損失を引き起こす可能性があります。そのため企業によっては、ChatGPTやGoogle BardといったLLMの業務使用禁止を命じているケースも見られます。
建設業におけるLLMの活用事例
ここでは、建設業におけるLLMの活用事例についてご紹介します。DX推進の一環として、建設業に特化したツールの開発が進められています。
安藤ハザマ
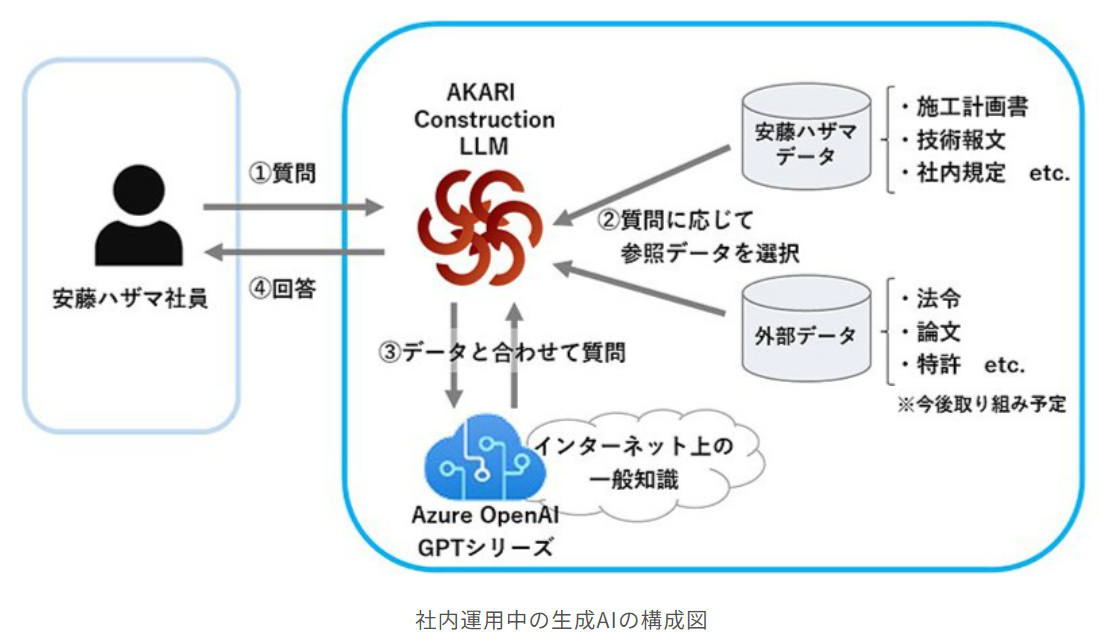
安藤ハザマは、DXソリューション企業の燈と協業して、建設分野に特化した生成AIの社内運用を開始しました。「AKARI Construction LLM」に、施工計画書や技術文書などの社内ノウハウを取り込んでいるのが特徴です。
これにより、建設分野の専門的な内容に関しても正確な情報を得られるようになります。また回答の生成に用いた文書を明示する機能を備えているため、さらなる業務効率化や的確な業務判断が可能になっています。
今後は手書き文書のデータ化や、特許・論文・法律等のデータベースとの連携も進める予定です。安藤ハザマ独自の生成AIの開発を進めることで、さらなるDX化を実現していきます。
西松建設

西松建設でも、安藤ハザマと同様に燈の「AKARI Construction LLM」を導入して業務利用を開始しています。これにより建設事業における文書生成AI活用を飛躍的に促進し、業務効率化や文書の品質向上につなげます。
この生成AIは自然言語処理技術を用いた高度な文章生成能力を持ち、短時間で高品質な文章を生成できるのが特徴です。セキュアな文章生成AI利用環境を整備することで、社内問合せの効率化など様々な社内ナレッジの活用を進めます。
CONOC

建設DX企業のCONOCは、ChatGPTをはじめとするLLMを活用した建設業向けDXコンサルティング事業を開始しました。具体的には、複数のお客様と共同で以下の取り組みを行っています。
- 建設業界従事者向けの社内学習サービス
- 工事におけるプロセスの可視化と、工程表作成の自動化
- 要件に対して最適な見積もりを自動的に生成するサービス開発
工事におけるプロセスや工程表作成等にLLMを活用することで、より専門性を要する業務への注力が可能になります。業務効率化だけでなく働き方も進化させるべく、お客様のご要望に合わせた提案をして行く予定です。
まとめ
LLM(大規模言語モデル)はChatGPTにも活用されており、日々進化を遂げています。中でも建設業に特化したLLMは、業務効率化だけでなく知識の継承にもつながる重要な技術です。ただし情報漏洩や情報の不確実性といった課題も残っているため、さらなる改善が求められています。
